Old pattern powering modern tech.
Or why modern storage is just a faster tape.

On March 23rd I was honored to present at PAC HERO FESTIVAL 2021 my favorite append-only design property. The recording is available on YouTube and this article contains some of its highlights.
A little history
When looking for the best learning investments, I like using wise business principle practiced by Jeff Bezos:
I very frequently get the question: 'What's going to change in the next 10 years?' And that is a very interesting question; it's a very common one. I almost never get the question: 'What's not going to change in the next 10 years?' And I submit to you that that second question is actually the more important of the two - because you can build a business strategy around the things that are stable in time.
On the surface technology is advancing extremely fast, but most of it is powered by fairly stable foundations and a quick dive into history may reveal one of them.
Due to technological limitations, namely inability to delete, early writing approaches could only append text and pictures:



But even in modern days disciplines with high cost of mistakes like accounting are still relying on append-only techniques with its double entry accounting:

Magnetic tape was first used to record computer data in 1951 on the Eckert-Mauchly UNIVAC I and, since random reads required expensive seeks, it promoted sequential access patterns and showcased the power and value of append-only data structures.

Why is new storage just a faster tape?

This is all great, but these days we have HDD, SSD, NVMe, RAM and cache at our disposal and they don't seem to look anything like magnetic tape. But let's take a look under the hood. For the most part, when we think about IO, we reason in terms of IO libraries that may handle buffering and delegate to syscalls like write to take care of the magic responsible for dealing with hardware.
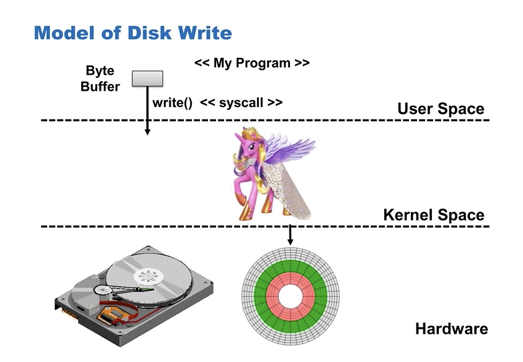
Unfortunately, IO picture is significantly more complex, includes user/kernel level buffers, many system calls and does not have a unicorn:
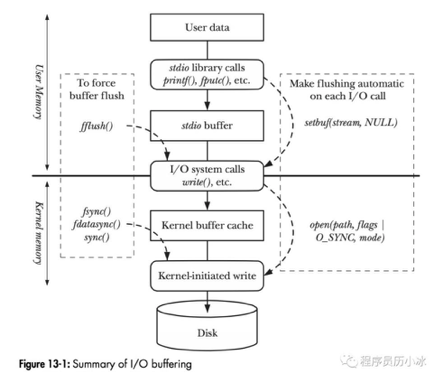
In fact it's much more complex than that
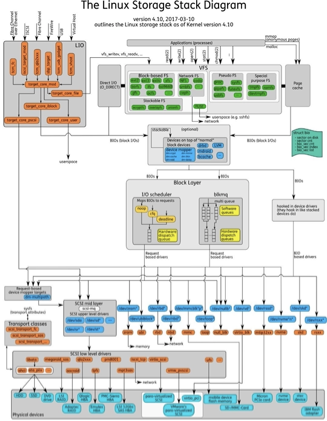
with numerous user and kernel space abstractions responsible for buffering, caching, prefetching, batching and other aspects responsible for efficient, reliable IO with consistent APIs hiding underlying hardware complexity. There are 2 types of complexities though:
- essential, which is inherent to the domain
- accidental, which is just a side-effect of the implementation
Similar to how being ignorant to underlying database and network layer backing up an API we use can lead to N+1 query problem, not recognizing block structure, prefetcher and controller cache leads to read/write amplification, corrupted data and poor performance.
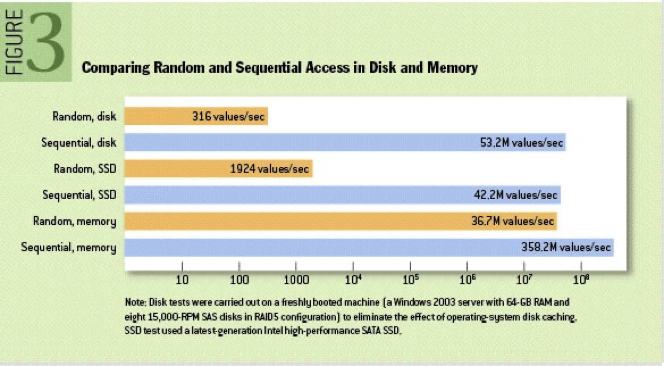
As we've established before, expensive seeks result in significant performance difference between sequential and random access for magnetic tapes. Since HDDs rely on mechanical parts that negatively impact their seek timings, we expect to see speed disparity similar to magnetic tapes. But surely that's no longer the case with modern NVMe devices? Turns out, it's still the case!
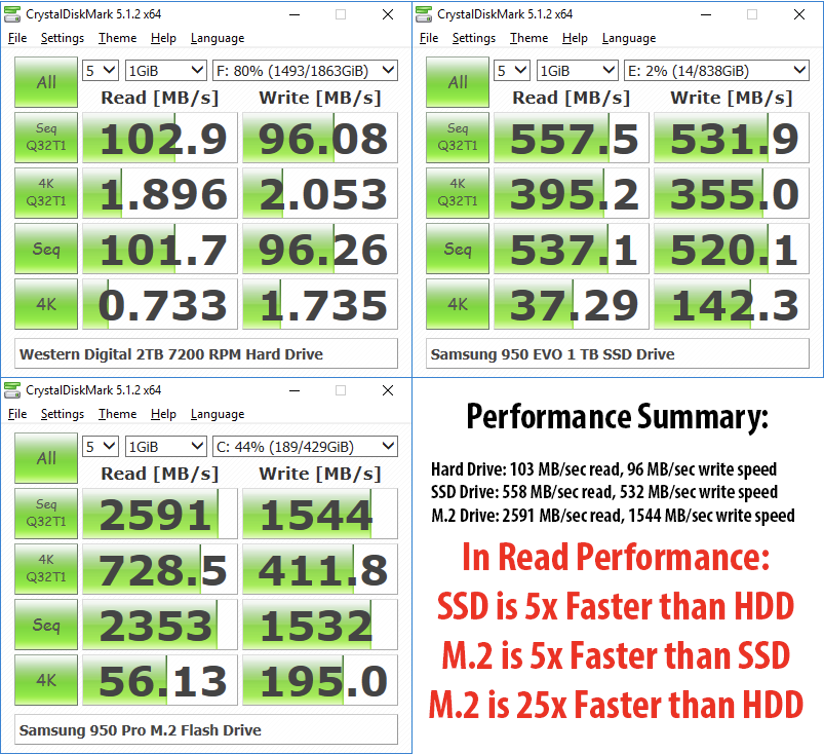
But how come? SSDs no longer have any mechanical parts, so random access should no longer involve expensive seeks, so what would explain these numbers?
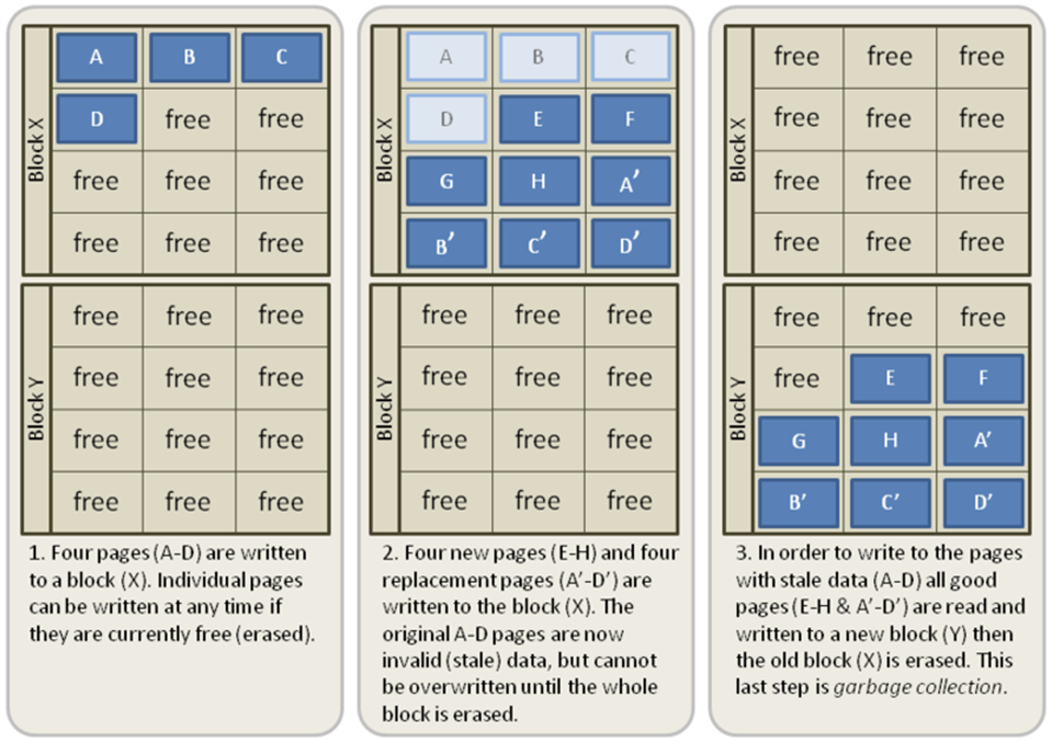
The short and somewhat simplified answer is block structure and difference in how HDDs and SSDs handle writes causing write amplification. While HDD’s write data on empty space, SSDs erase data first before writing new data inside Flash storage chips. This process involves data and metadata being written multiple times because Flash storage consists of data blocks and pages.
Blocks are made out of pages and pages are made out of storage chips. Unfortunately Flash cells can only be deleted block-wise and written on page-wise. To write new data on a page, it must be physically completely empty. If it is not, the content of the page has to be deleted, but it's not possible to erase a single page, instead all pages that are part of the block have to be deleted. Since SSD block sizes are fixed, e.g. 512kb, 1024kb up to 4MB, a single block containing a page with only 4k of data, will take the full storage space of block size anyway. And that's not the only problem. On every data change, the corresponding block must first be marked for deletion then the read/modify/write algorithm in the SSD controller will determine the block to be written to, retrieve any data already in it, mark the block for deletion, redistribute the old data, a and transfer new data to the old block.
Retrieving and redistributing the new data means that the old data will be copied to a new location and other complex metadata coping and calculations will also add to the total amount of data.
The result is that by simply deleting data from an SSD, more data is being created than being destroyed.
Block structure is also one of the reasons why sequential access is faster even for RAM:
Understanding and taking advantage of such hardware properties is part of the mechanical sympathy coined by Jackie Stewart, F1 racing driver:
You don’t have to be an engineer to be be a racing driver, but you do have to have Mechanical Sympathy.

These block properties do not stop at the macro-level of storage devices and go all the way to caches and CPU instruction processing.
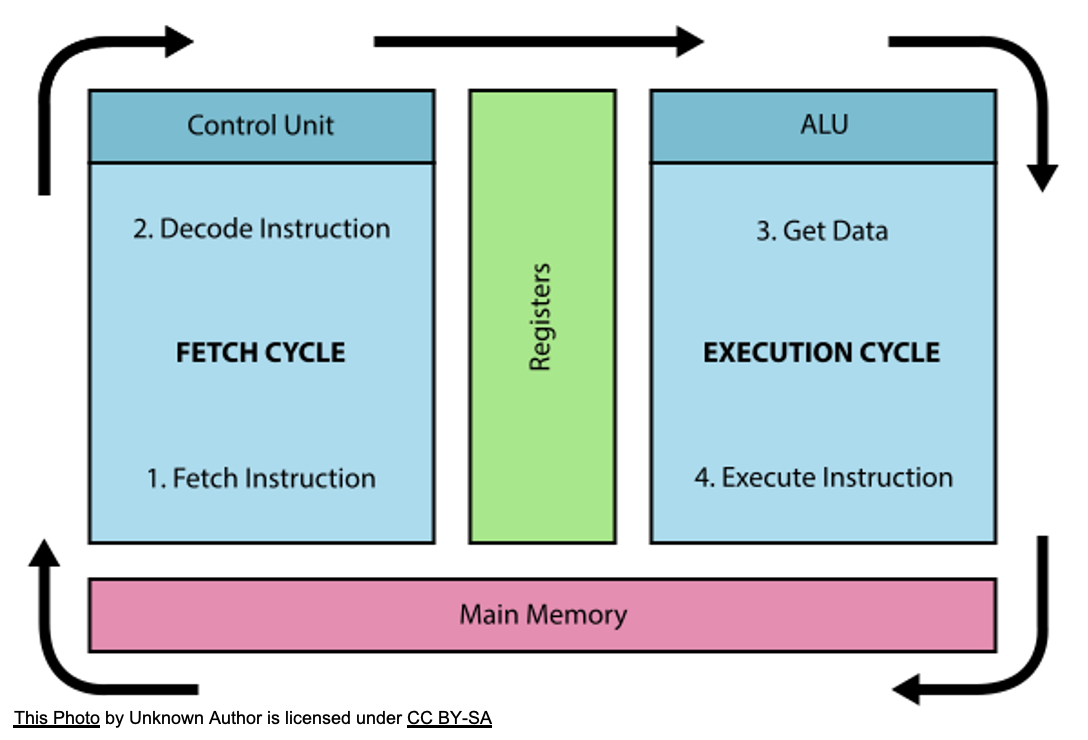
CPU’s instruction fetcher fetches the machine code in chunks of 16-bytes (16B), 32-bytes (32B) or 64-bytes (64B) instructions (depending on the processors and their generations) in each clock cycle, feeds them to the instruction decoder, convert the decoded instructions to micro-operations (μops) and finally execute those μops. Because of this, in some cases it pays off to insert NOP instructions to make sure that hot code is aligned to chunk size, e.g. mod 16, mod 32 or mod 64, to fetch maximum amount of the hot code in minimum number of clock cycles.
Another important advantage sequential predictable data layout brings to CPUs is data prefetching efficiency.
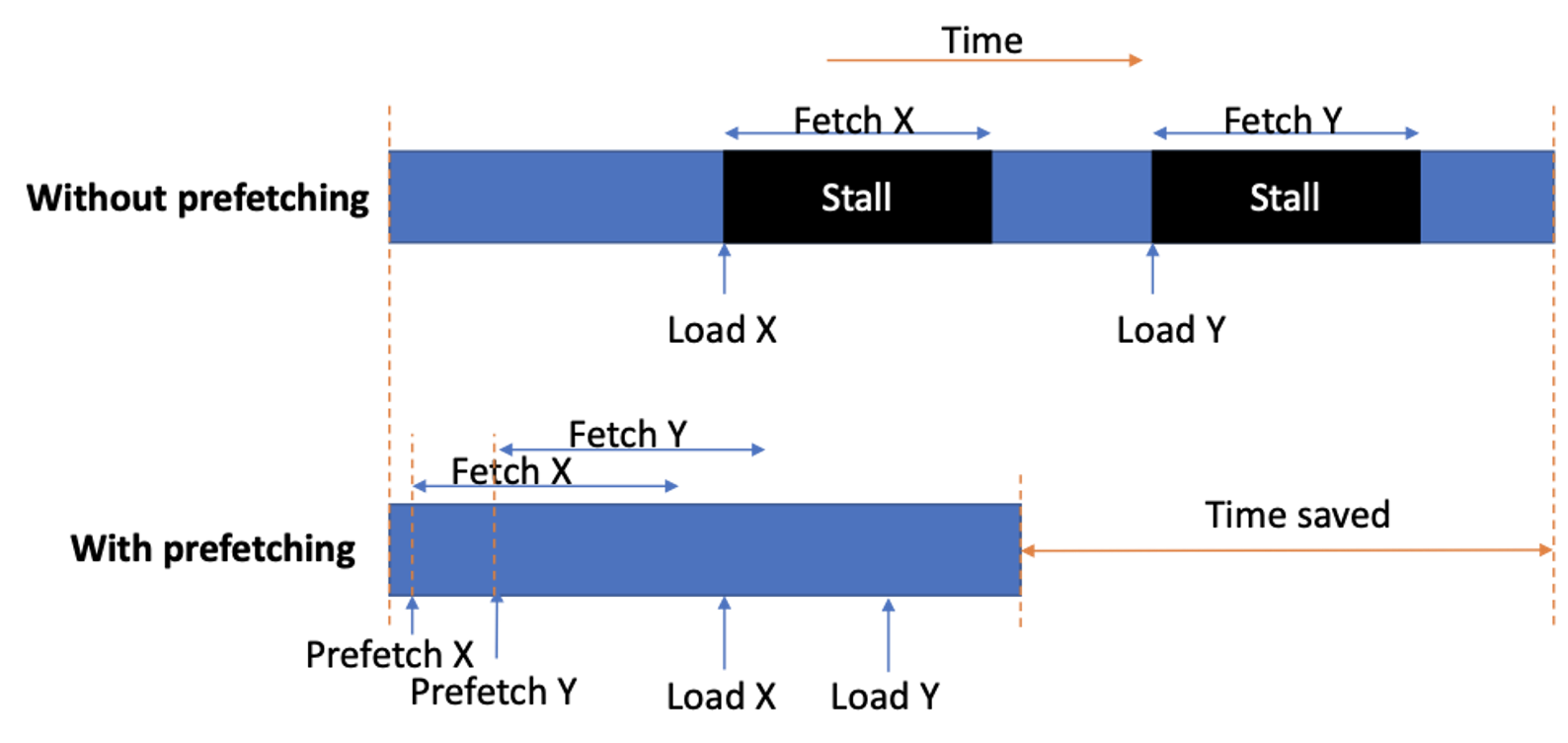
One of the biggest bottlenecks in processors is the long memory access latencies. While caches are effective in minimizing the number of times a processor accesses memory, some applications simply do not fit in the on-chip caches and end up frequently accessing the memory. These applications tend to spend a significant portion of their run times stalled on memory requests. Data prefetchers can help relieve this bottleneck by fetching the lines from memory and putting them in the caches before they are requested. Data prefetchers are now an integral part of any high-end processor contributing a significant portion to their single-thread and multi-thread performance.
This explains why matrix access patterns have such a significant impact on performance:
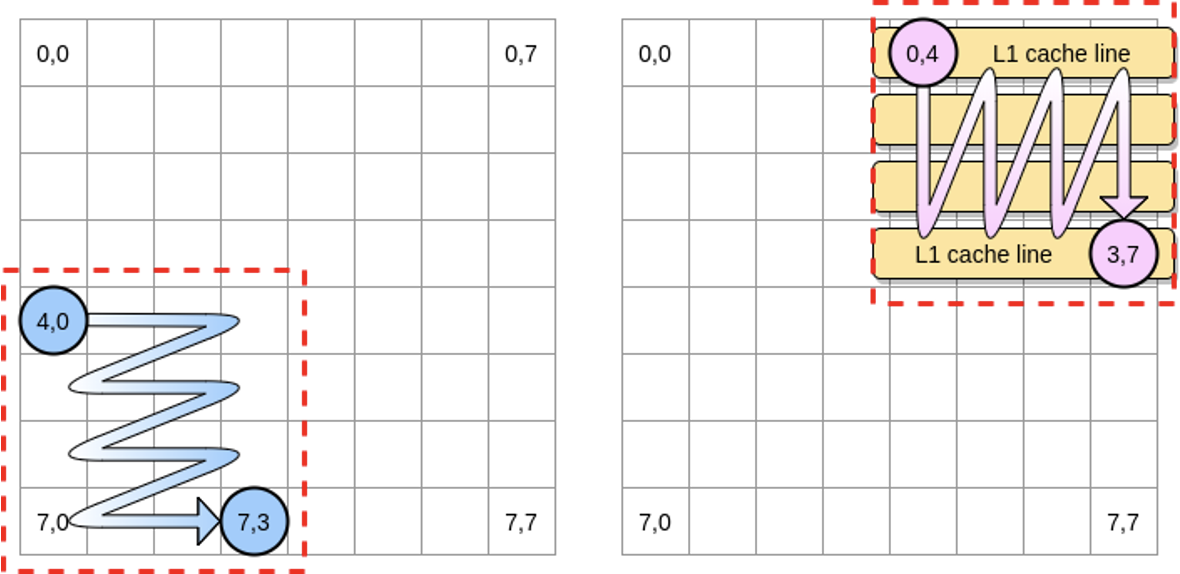
BenchmarkMatrixReversedCombination-64000 2 573121540 ns/op
BenchmarkMatrixReversedCombinationPerBlock-64000 6 185375690 ns/op
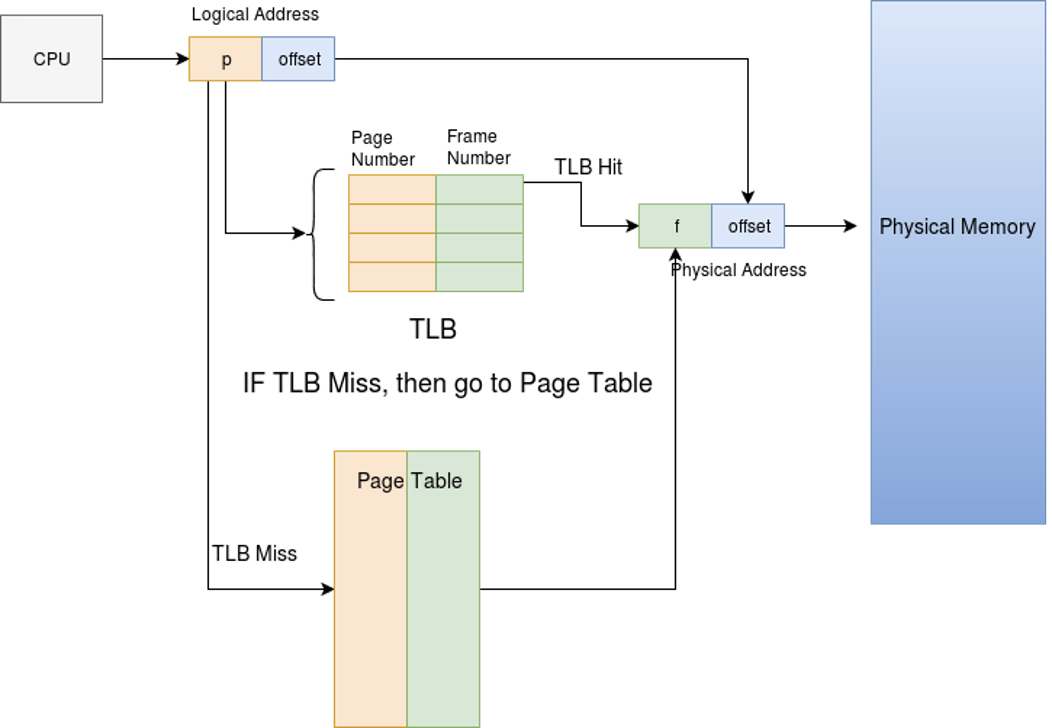
Sequential data access also plays well with TLB responsible for translating virtual memory addresses into physical ones.
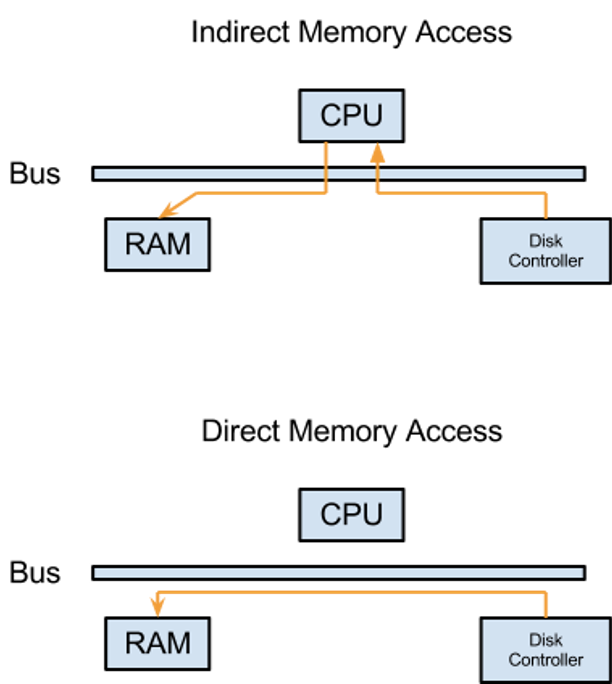
Better yet, is to not involve CPU in data transfers at all and leverage DMA controller instead, but a significant number of older versions support only data occupying sequential memory pages.
This requirement led to development of clever ways to simulate sequential data layout with virtual memory mapping shenanigans offered by projects like cbuffer:
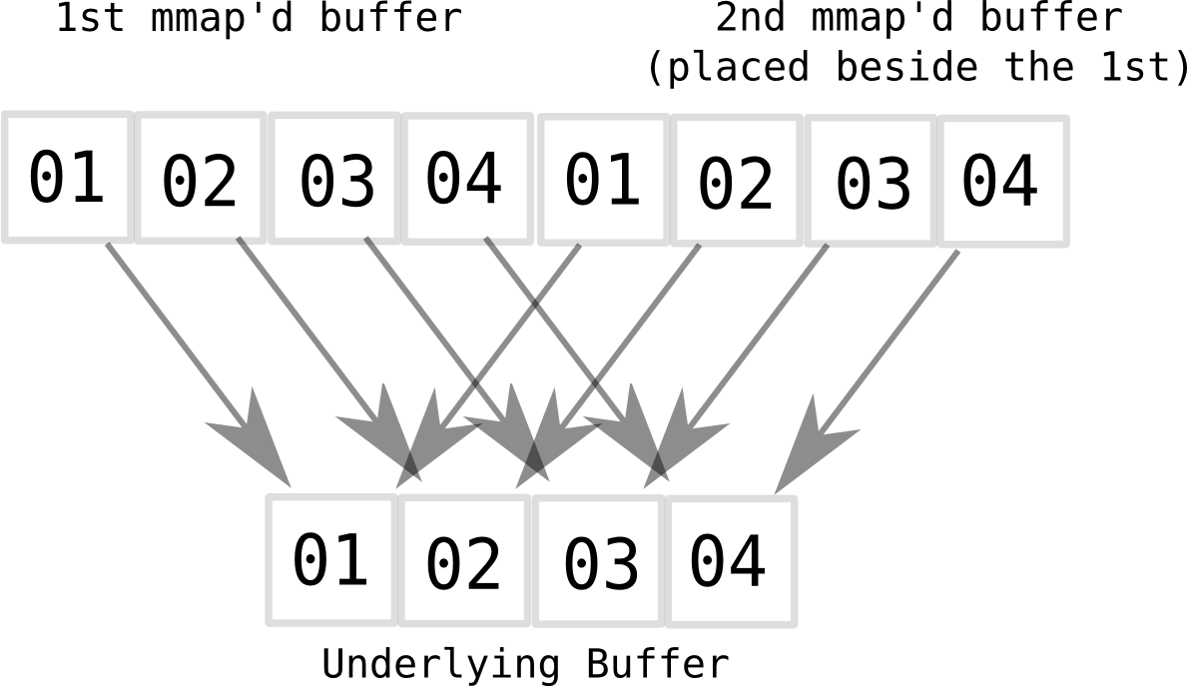
It creates a second virtual mapping right after the first enabling free wrap-around logic without having to deal with complexities of incomplete data writes at the end of the buffer and modular arithmetic.
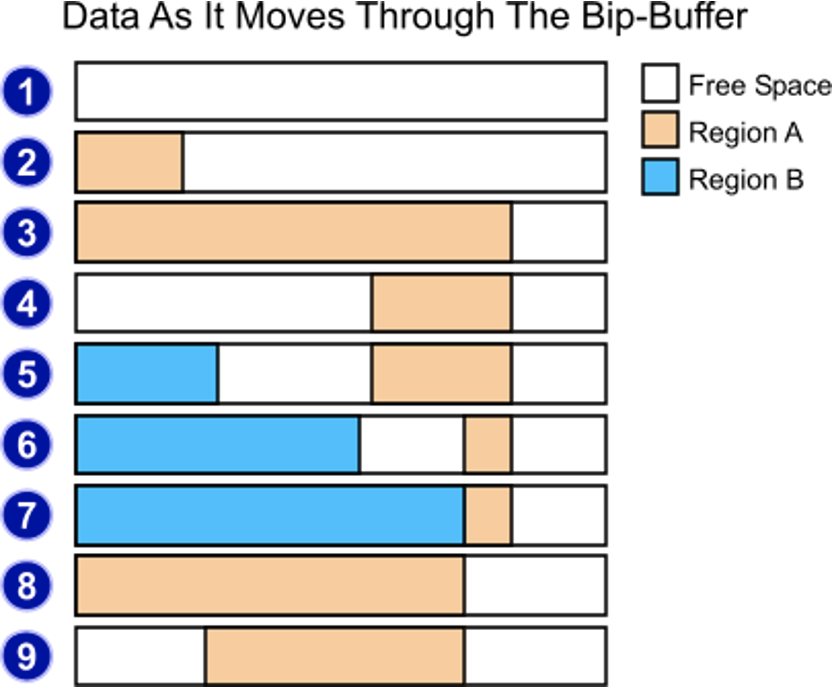
There is also its modern version called Bip-buffer that is using two regions to achieve the same sequential layout without mmap hacks:
Modern applications
What do projects like Disruptor, Aeron, Kafka, Raft, InfluxDB and io_uring have in common?
They all leverage sequential access patterns for efficient caching, prefetching, writes and lock-free data structures. For instance, homogeneous data often enables delta-encoding, which can be compressed even further using run-length encoding:

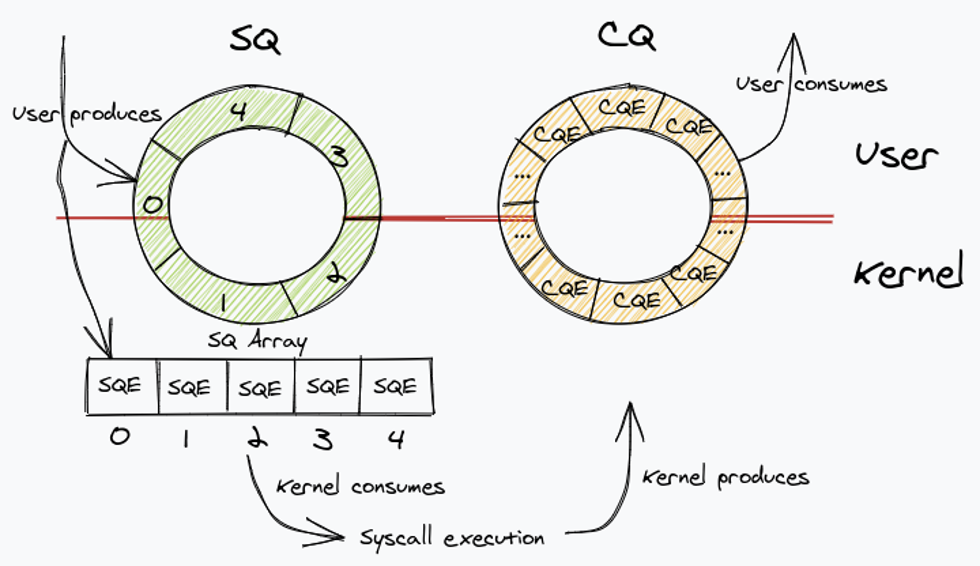
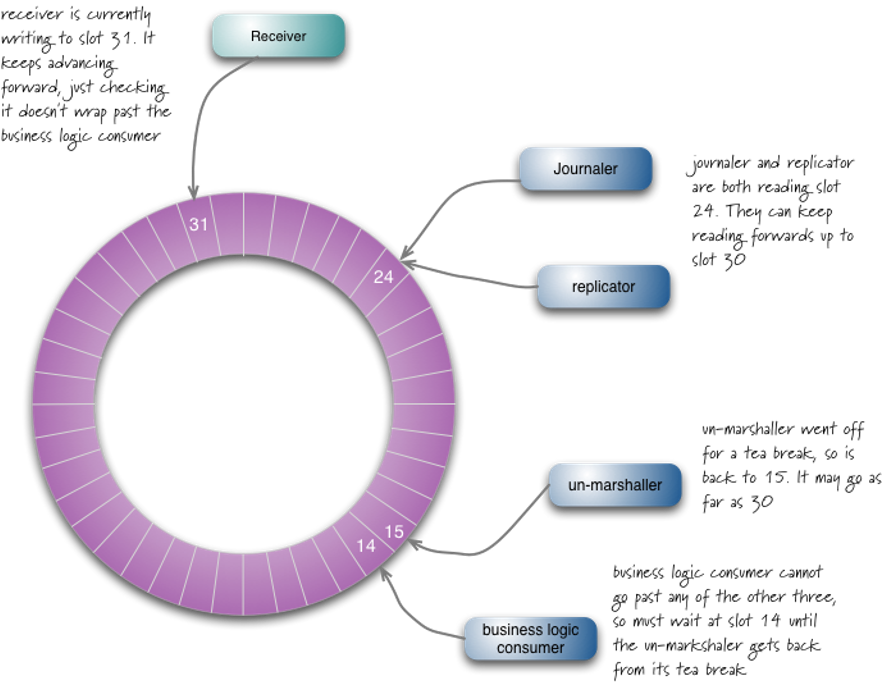
The same append-only principle also powers an extremely useful, lock-free data structure used for efficient transfer of data and tasks from producers to consumers - ring buffers. For example, io_uring uses ring buffers for lock-free zero copy communication between kernel and user space:
Similar append-only approach is also used for lock-free message transfers in Aeron/Argona:
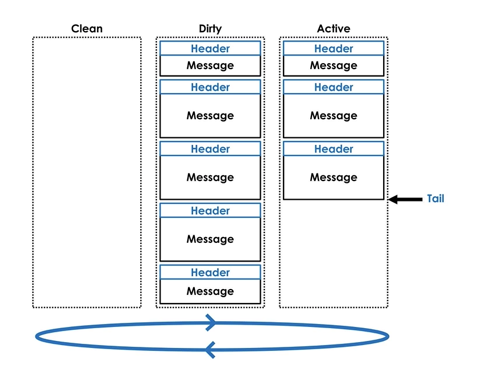
The reason why append-only design is lock-free friendly is because all writers have to do to allocate storage is atomic increment readily available in all modern programming environments:

These properties are a secret behind impressive performance of Disruptor:

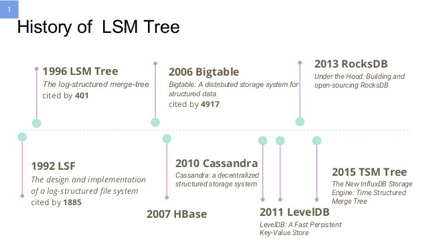
Another extremely impactful append-only data structure is log structured merge tree that despite their relative short history power Bigtable, HBase, Cassandra, LevelDB, RocksDB, TSM Tree and many other database solutions.
In general, there are 3 major metrics to measure performance of a data structure: write, read and space amplification, so optimal choice depends on the most common use-case. Level-based LSM-tree has a better write performance than B+ tree while its read performance, despite compaction, is not as good as B+ tree. At the same time, it is much easier to improve read performance using caches, but it's much harder to speed up writes.

Interestingly it's possible to implement B-Trees using append-only approach. For instance all nodes of a following tree
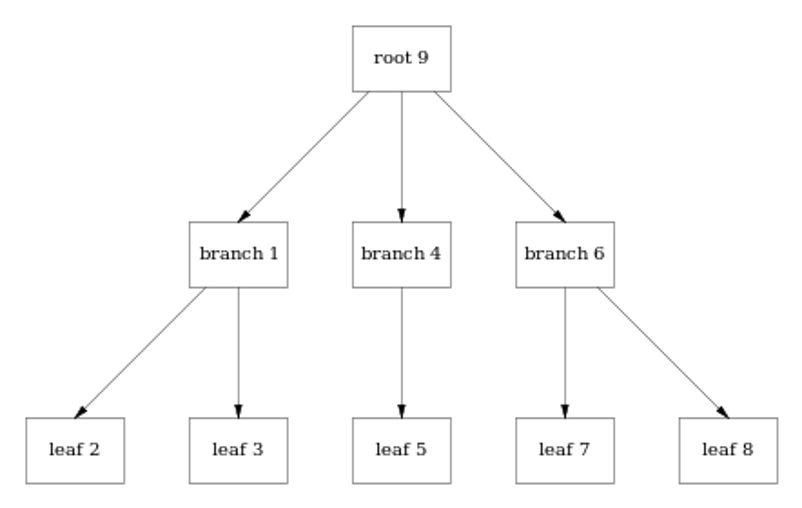
can be written and linked in a sequential way

Similar to persistent data structures addition of a node does not mutate an existing tree but creates a new metadata, root and internal nodes on the path from changed leaf to the root:
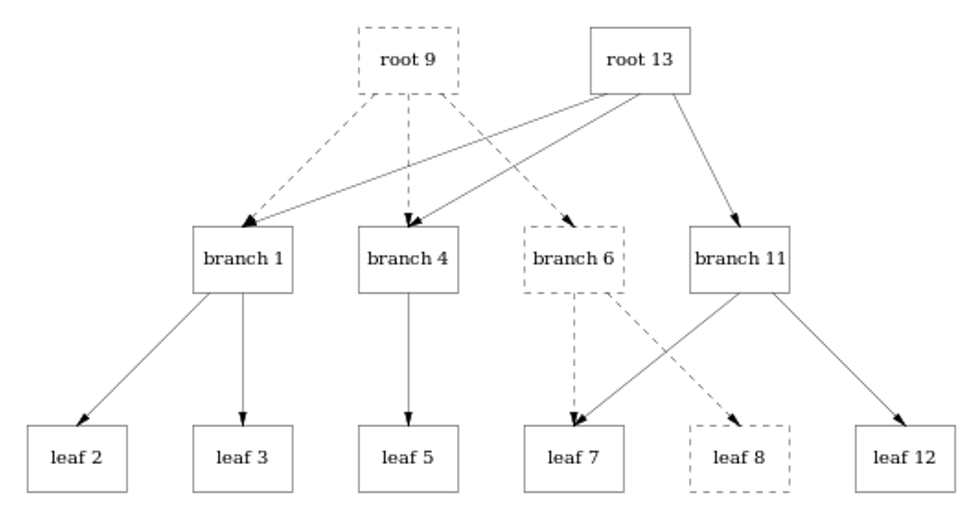
All these nodes are simply appended to existing log file
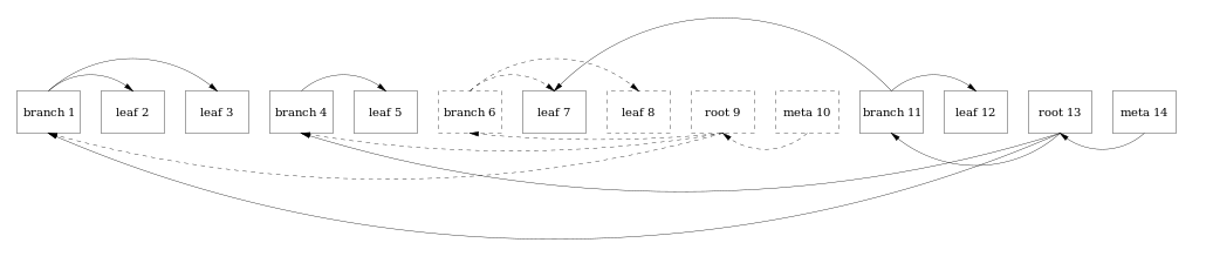
In addition to great performance, this type of storage also brings Multi-Version Concurrency Control for free, since all clients can continue using the tree roots they used at the beginning of the transaction.
The trade-offs between read and write performance are so common and having a transaction ledger is so useful, that append-only approach found its way into domain driven design under the name of Command Query Responsibility Segregation (CQRS). Separating commands (writes) from queries (reads) makes it possible to build optimized solutions for each use-case. In fact, there can be multiple query projections specialized to serve most common requests.
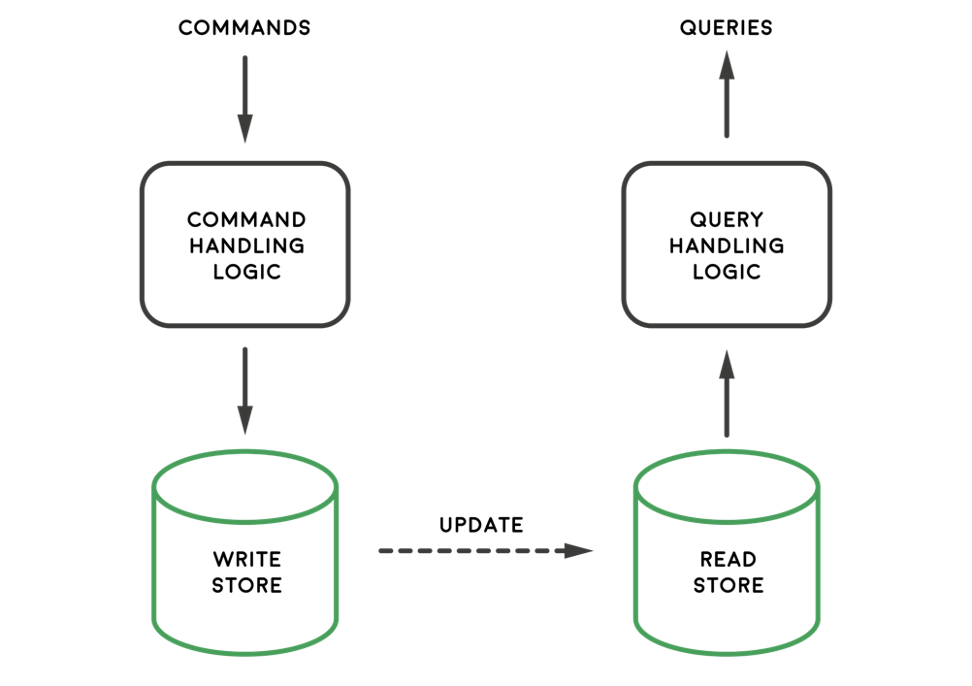
Instead of summary
Benefits of append only:
- Lock-free
- Zero-copy
- Prefetching
- Branch prediction
- Single-writer pattern
- Reduced wear & tear
- Compression
- JVM JIT sequential pattern optimization (list -> array)
Takeaways
- Prefetch and use speculative execution
- Keep in mind block structure, but don’t forget about false sharing
- Use flyweight pattern with zero-copy
- Compress your data: CPUs are very fast and often have spare cycles
- Avoid locks: use single-writer design and lock-free data structures
- Avoid branches or make them predictable: sort data, use insertion sort for small datasets)

