Column-oriented processing.
Learning from DBMS series.

It's tempting to believe that there is a single unifying theory of everything and while we haven't found it yet, there are numerous principles shared between different disciplines responsible for significant performance wins. With this post I'd like to start a series covering such principles.
Columnar database management systems (DBMS) store data tables by column rather than by row.
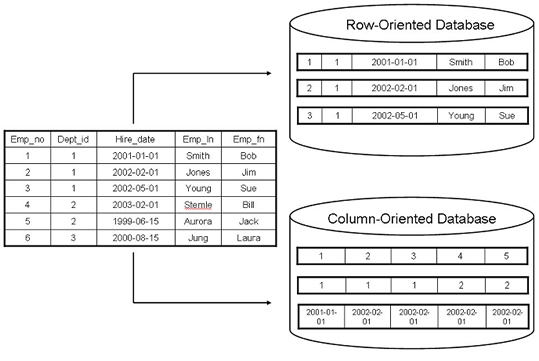 This way of storing data has many advantages for online analytical processing, including:
This way of storing data has many advantages for online analytical processing, including:
- less IO. Since data is read in pages, in case of row-based storage, in addition to requested column, OS would also fetch other columns that are part of rows.
- cache-friendly. Cache space is not wasted on storing unnecessary columns.
- encoding-friendly. Delta-encoding, run-length encoding, delta-of-delta and ZigZag encodings are just a few schemes that are used to significantly reduce storage requirements.
Turns out that a very similar approach known in game development as a parallel array, where instead of array of structs, a struct of arrays is used. In Go this would look something like:
type User struct {
name string
age int
}
type Users []User
vs
type ParallelUsers struct {
names []string
ages []int
}
The benefits of such organization while doing linear scans of age values like in the function below
func SumUserAges(users Users) uint64 {
var total uint64 = 0
for _, user := range users {
total += uint64(user.age)
}
return total
}
are very similar to those of columnar storage in DBMS:
- reduced IO. While doing a linear scan over
agesonly relevant data will be fetched from memory. - cache-friendly. Only age values are stored in cache, they are also loaded in blocks and cache prefetcher is effective at speculative loading of age values that are going to be used soon.
- vectorization. Compilers are able to leverage SIMD instructions to perform additions on of multiple
agevalues.
To be continued...


